Scene-Aware Background Music Synthesis(2020)
描述了一种根据视觉内容合成背景音乐的方法。过程分两步:场景视觉分析与音乐合成。场景视觉分析通过深度学习实现,即利用神经网络分析输入场景图像的情感。实时的音乐合成通过优化方法实现,损失函数用于引导音乐片段的选择与转变顺序,使得合成音乐尽可能具有与视觉内容一致的情感,并尽量在场景切换时保持连续性。
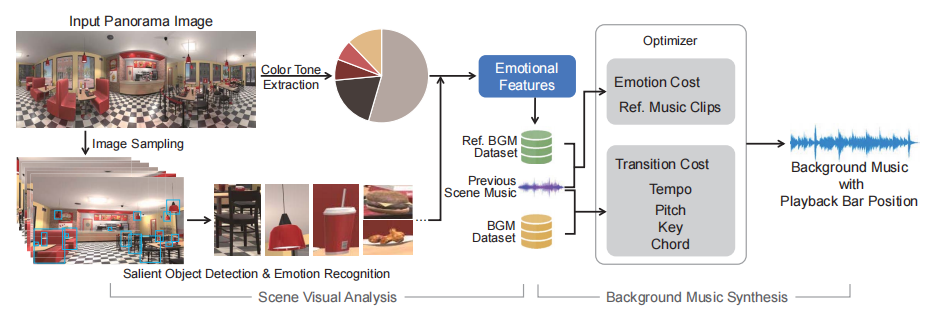
Scene Visual Analysis
本方法的场景视觉分析一步主要从图像中提取两个情感要素:显著对象的情感特征以及颜色色调特征。图像中的显著对象可以通过基于VGGNet的模型检测出来。而对检出对象的情感特征判定则是利用一个类似AlexNet的模型实现的,其在一个对图像标注有“积极”“消极”的数据集上预训练。颜色色调特征(即图像的代表颜色)是通过计算并简化图像的颜色凸集获得的,在具体实现中,颜色的种类取定为5。
Background Music Synthesis
为了将多个音乐片段合成为过渡自然的片段,作者将音乐生成过程规范成了一个有着各种约束条件的优化问题,这些约束包括情感、和弦进行、节奏等等。场景转换时需要为已合成音乐选择后继音乐片段,这一优化过程以小节为单位进行。损失函数由两项组成:一项衡量所选后继音乐片段与新场景之间的情感一致程度,一项衡量已合成音乐到该音乐片段的转变是否突然。后一项损失值主要考虑了小节中的音高、调式、节奏以及和弦进行这四个音乐内容要素,使得演奏到第m小节的已合成音乐和所选取后继音乐的第m*小节之间的过渡尽量自然。
本方法需要两个数据集实现:一个数据集含有场景和背景音乐的组合,用于训练;另一个含有1000条音乐片段,用于合成音乐。
Video Background Music Generation with Controllable Music Transformer(2021)
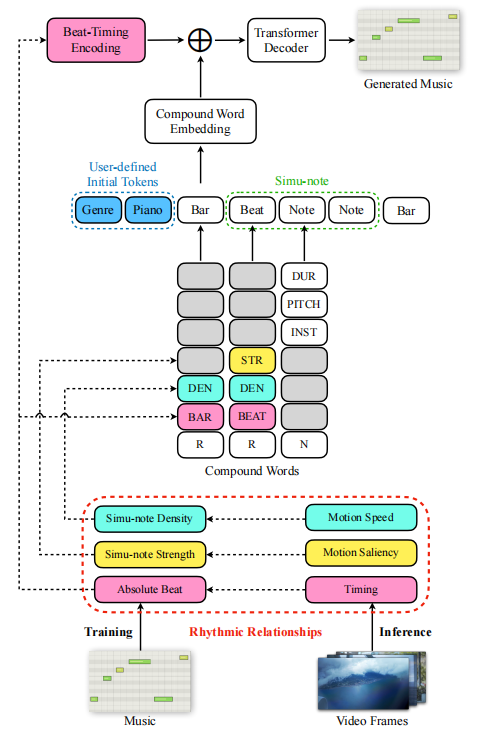
下文中音符指的是simu-note,有时候人们也称之为和弦,总之就是同一时刻一起发声的一系列音(note)
本方法强调为视频自动生成背景音乐,相比之前的工作能够更好地为视频生成特定的音乐,并考虑到了音乐的节奏和视频的节奏应具有的一致性。作者首先建立起视频和背景音乐之间的节奏联系,具体来说就是将视频的时间点、动作速度、动作显著度以及音乐的节奏、音符密度和音符强度一一对应。接着作者提出了一个可控制的Music Transformer模型(CMT),其能够接受前面提到的节奏信息输入来对生成音乐的节奏进行局部的控制,也能够接受用户提供的音乐流派以及演奏乐器的输入来对生成音乐进行全局控制。
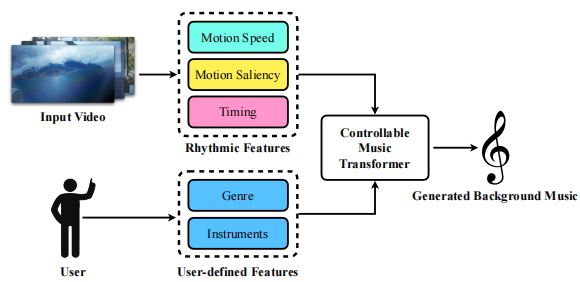
Establishing Video-Music Rhythmic Relations
本方法建立视频与音乐之间节奏联系的内容有三部分:视频计时(timing)与音乐节拍,运动速度与音符密度,以及运动显著度与音符强度。
1)视频计时与音乐节拍的联系实际上就是将视频第t帧的序号t通过视频的FPS信息以及音乐的速度信息(Tempo)来换算出这一帧在音乐中对应第几拍(以四分之一音符为一拍)。
2)动作速度与音符密度的联系需要首先检测运动目标。本方法利用光流法来检测并衡量某帧中运动的幅度;在开始时视频被划分成多个片段,该帧所在的视频片段中这一运动的速度就是其平均光流幅度。得到运动速度后,音乐的音符密度就需要与运动速度相一致,即运动速度较快的视频片段所对应的音乐应该是音符演奏较密集的。音符密度以小节为单位衡量,前面提到的视频片段划分与音乐的小节是对齐的,即划分出来的一个视频片段应对应生成音乐的一个小节。
3)某帧的动作显著度定义为两个级联的帧中各个方向上光流变化的绝对值。而音符强度指的是一个音符中有几个音,直观来说就是一个和弦听起来有多繁。作者在动作显著度与音符强度之间建立了一个正相关联系。
Controllable Music Transformer
CMT框架如下图所示:
文档信息
- 本文作者:Jingwen Huang
- 本文链接:https://uangjw.github.io/2022/11/15/paper-scene-aware-music/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)