主要参考陈旭老师的ppt以及知乎专栏https://www.zhihu.com/column/reinforce
MDP未知具体来说就是$R(s,a)$与$P(s’$|$s,a)$是未知的;在现实生活中,MDP模型要么是未知的,要么是已知但实在是太大太复杂了。所以不基于模型的预测与控制方法是必要的。
Model-free RL是通过与环境交互来学习的。在这里需要引入一个episode(又称trajectory,老师称之为“轨迹”)的概念,episode是agent通过与环境交互得到的一个集合,其内容可以表示为
${S_1, A_1, R_1, S_2, A_2, R_2, … S_T, A_T, R_T}$
Model-free Prediction
这里不基于模型的预测指在一个未知的MDP上估计一个policy的价值。课堂介绍了两种方法:
Monte Carlo policy evaluation
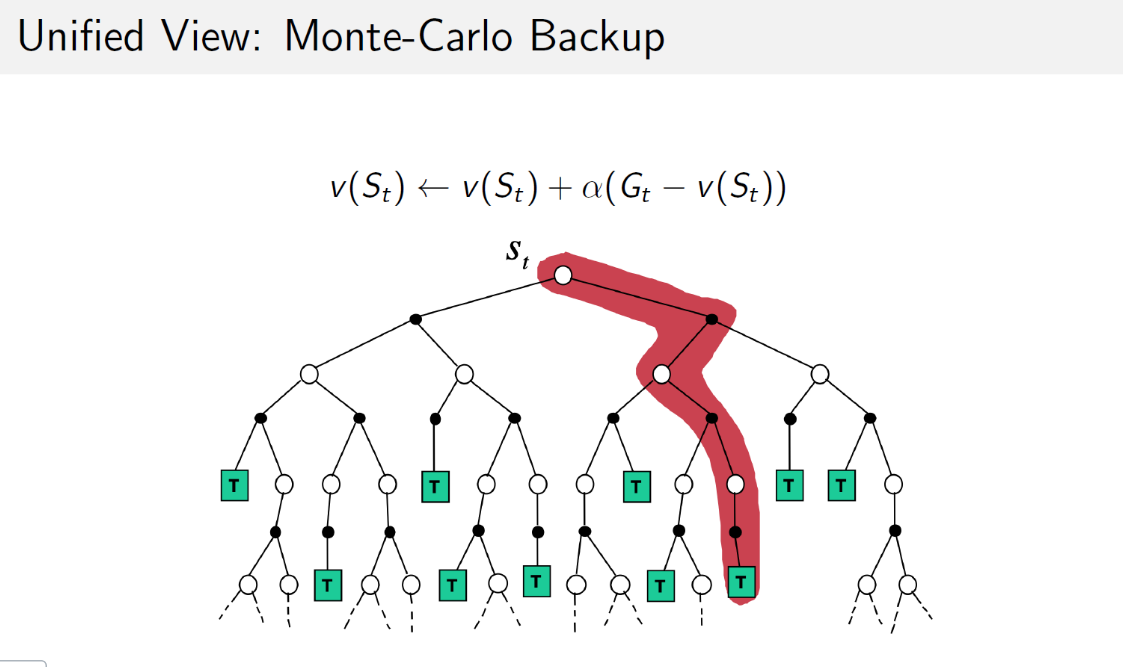
蒙特卡洛策略评估的目标是,在给定的policy下,从一系列完整的episode中学习得到该policy下的状态价值函数。其特点是使用有限的完整episode产生的经验性信息推导出每个状态的平均收获,以此来替代收获的期望即状态价值。
基于特定policy $\pi$的一个episode信息可以表示为如下的序列
${S_1, A_1, R_2, S_2, A_2, R_3, …, S_t, A_t, R_{t+1},…,S_k}$ ~ $\pi$
注意这里$R$的下标与前面介绍episode的下标不一样,这里$R_{t+1}$表示的是$t$时刻个体在状态$S_t$获得的即时奖励。更准确地说是个体在状态$S_t$执行一个行为$a$后离开该状态获得的即时奖励。
$t$时刻状态$S_t$的收获:
$G_t=R_{t+1}+\gamma R_{t+2}+…+\gamma^{T-1}R_T$
其中$T$为终止时刻。于是该policy下某一状态$s$的价值就可表示为
$v_{\pi}(s)=E_{\pi}[G_t$|$S_t=s]$
Incremental MC Updates
在状态转移过程中,可能发生一个状态经过一定的转移后又一次或多次返回该状态。一个在实际操作中常用的方法就是把Incremental Mean方法应用于蒙特卡洛策略评估,得到蒙特卡洛累进更新方法。
对于一系列episode中的每一个episode,对这个episode里的每一个状态$S_t$,有一个收获$G_t$,每碰到一次$S_t$,使用下式计算状态的平均价值$V(S_t)$:
$V(S_t)\leftarrow V(S_t)+\frac{1}{N(S_t)}(G_t-V(S_t))$
其中$N(S_t)$就是遇到这个状态的次数,整个episode信息分析完毕后$V(S_t)$就是所有$S_t$的收获的平均值。在处理非静态问题时,使用这个方法跟踪一个实时更新的平均值是非常有用的,可以扔掉那些已经计算过的episode信息。此时可以引入参数$\alpha$来更新状态价值:
$V(S_t)\leftarrow V(S_t)+\alpha(G_t-V(S_t))$
Temporal Difference (TD) learning
MC方法其实有很多缺点,实际应用并不多;时序差分(TD)学习方法才是实际常用的。TD学习也从episode学习,但它可以学习不完整的episode,通过自身的bootstrap来猜测episode的结果,同时持续更新这个猜测。
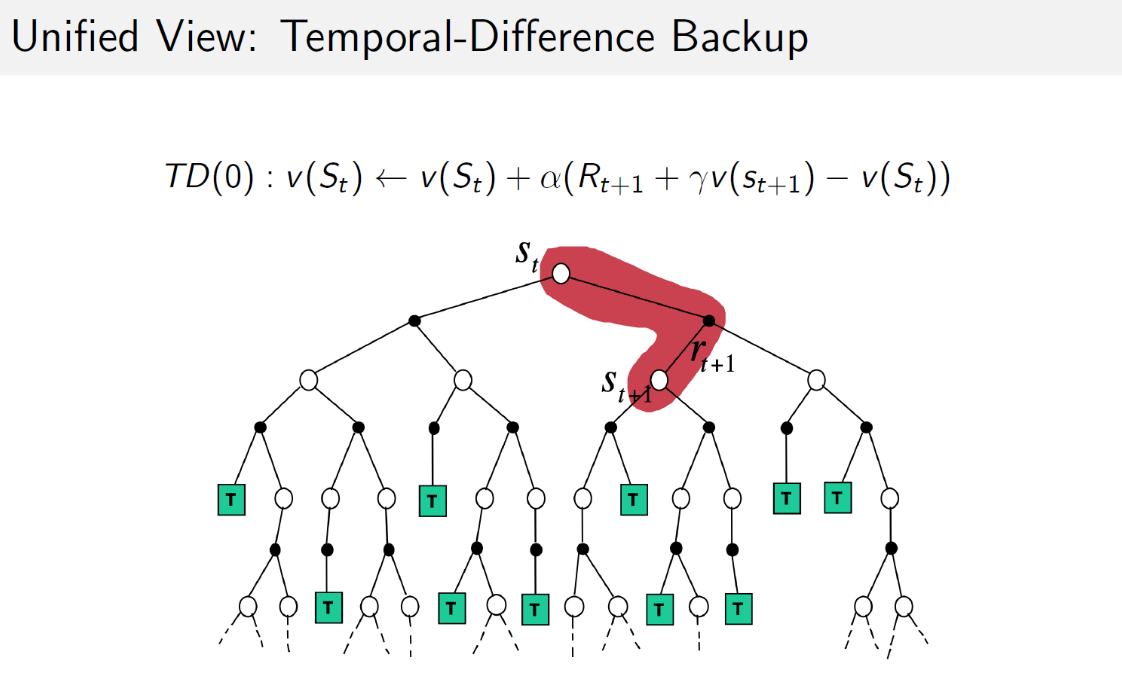
TD学习中算法在估计某一个状态的价值时,用的是离开该状态的即刻奖励$R_{t+1}$与下一状态$S_{t+1}$的预估状态价值乘以衰减系数$\gamma$组成,符合Bellman方程的描述:
$V(S_t)\leftarrow V(S_t)+\alpha(R_{t+1}+\gamma V(S_{t+1})-V(S_t))$
式中:
$R_{t+1}+\gamma V(S_{t+1})$称为TD目标值
$\delta_t=R_{t+1}+\gamma V(S_{t+1})-V(S_t)$称为TD误差
bootstrapping指的就是TD目标值代替收获$G_t$的过程。可以理解为“引导”。
MC对比TD
一个episode中,TD在知道结果之前可以学习,MC必须等到最后结果才能学习;也就是说,TD可以在持续进行的没有结果的环境中学习。
MC使用的$G_t$是实际收获,是基于某一策略状态价值的无偏估计;而TD target是基于下一状态的预估价值计算的当前预估收获,是当前状态实际价值的有偏估计。如果用的是下一状态的实际价值来计算当前状态,那就是true TD target,是对当前状态实际价值的无偏估计:
$R_{t+1}+\gamma v_{\pi}(S_{t+1})$
TD算法使用了MDP问题的马尔可夫属性,在Markov环境下更有效;但MC算法并不利用马尔可夫属性,通常在非Markov环境下更有效。
MC/TD/DP
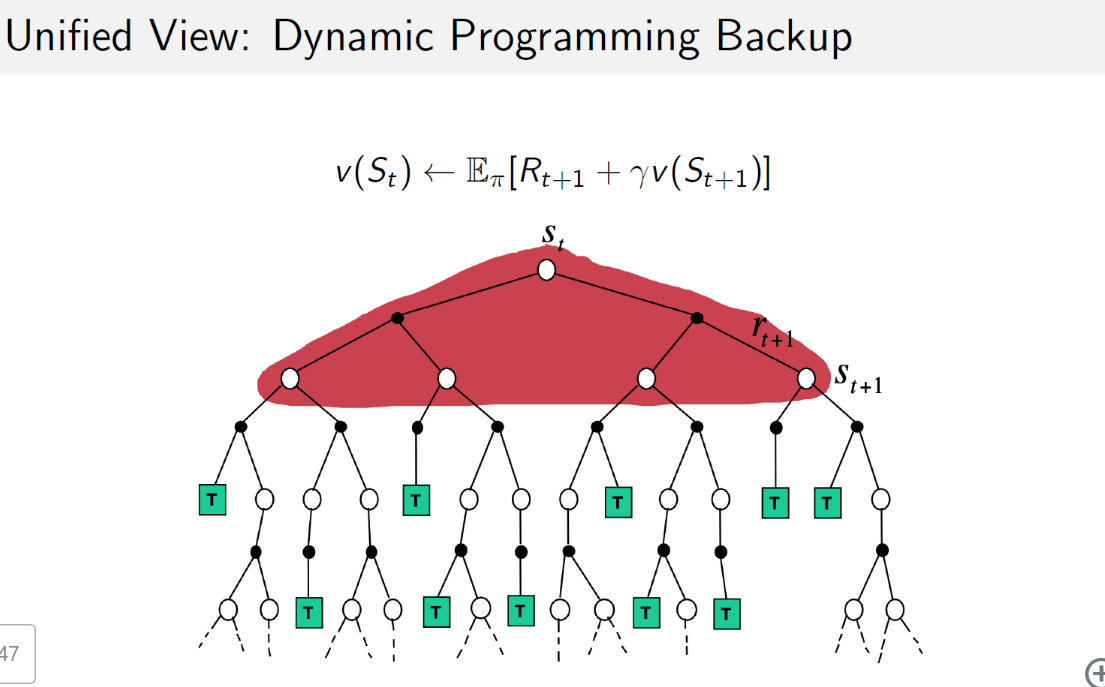
MC与TD与DP都是计算MDP模型的状态价值的方法。前两种是在模型未知的情况下的常用方法,MC要完整的episode来更新状态价值,TD不需要完整的episode;DP方法是在模型已知时使用的计算状态价值的方法,通过计算一个状态$S$所有可能的转移状态$S’$及其转移概率以及对应的即时奖励来计算这个状态$S$的价值。
MC没有引导数据,只使用实际收获;DP和TD都有引导数据。
Model-free control
这里不基于模型的控制指为一个未知的MDP最优化其价值函数。
Policy Iteration
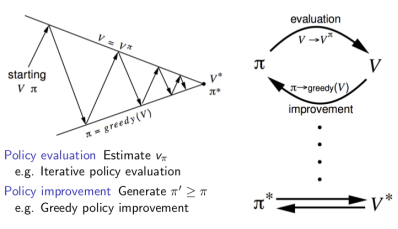
通用策略迭代的核心是在两个交替的过程之间进行策略优化。一个过程是策略评估,另一个是改善策略。从一个策略$\pi$和一个价值函数$V$开始,每一次箭头向上代表着利用当前策略进行价值函数的更新,每一次箭头向下代表着根据更新的价值函数贪婪地选择新的策略,说它是贪婪的,是因为每次都采取转移到可能的、状态函数最高的新状态的行为。最终将收敛至最优策略和最优价值函数。
这种方法不适用于模型未知的蒙特卡洛学习。我们需要使用状态行为对下的价值$Q(s,a)$来代替状态价值,这样做的目的是可以改善策略而不用知道整个模型,只需要知道在某个状态下采取什么样的行为价值最大即可。具体是这样:从一个初始的$Q$和策略$\pi$开始,先根据这个策略更新每一个状态行为对的$q$值,$s$随后基于更新的$Q$确定改善的贪婪算法。
但如果我们每次都贪婪地改善策略,很有可能会导致采样经验不足,从而产生一个并不是最优的策略。我们需要不时地尝试一些新的行为,$\epsilon$-exploration就是一个折中的探索方案:

SARSA: On-policy TD Control
SARSA算法是一种在控制问题中使用TD学习方法来获得状态行为价值$Q$的估计的算法。
SARSA是on-policy的:个体已有一个策略,并且遵循这个策略进行采样,或者说采取一系列该策略下产生的行为,根据这一系列行为得到的奖励,更新状态函数,最后根据该更新的价值函数来优化策略(一句话就是要优化的策略就是当前遵循的策略)。
伪代码:

在算法中,$Q(s,a)$是以一张大表存储的,这不适用于解决规模很大的问题。
Q-learning: Off-policy TD Control
off-policy与on-policy不同,off-policy的学习方法运行在两个policy上,一个target policy,一个behavior policy。off-policy学习是从behavior policy上采样得到经验从而改进target policy的,换句话说就是采用一个现有的policy,遵从它来与环境交互,获得数据,再利用这些数据来评估另一个policy。这种方法的好处能够在实际应用中体现出来,一个是能够从人类或其他智能体的经验中学习,另一个是能够从旧有的policy中学习。
Q-learning是一种基于TD的off-policy的控制方法,要点在于:更新一个状态行为价值$Q$时,采用的不是当前遵循策略的下一个状态行为价值$Q’$,而是采用待评估策略产生的下一个状态行为价值$Q’$。公式:
$Q(S_t,A_t)\leftarrow Q(S_t, A_t)+\alpha(R_{t+1}+\gamma Q(S_{t+1}, A’)-Q(S_t, A_t))$
其中TD target是基于待评估策略产生的行为$A’$得到的$Q$价值。
伪代码:

上面的伪代码展示的是一种,将完全greedy地改进policy(下一状态选择最大Q对应的a作为行动)作为target policy的Q-learning
文档信息
- 本文作者:Jingwen Huang
- 本文链接:https://uangjw.github.io/2021/10/24/RL-model-free-control/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)