三个基于深度学习的音乐转录模型
粗略了解三个模型,主要领会一下深度学习解决AMT问题的基本思想;总的来说本文是以下三篇论文的简要阅读笔记
An End-to-End Neural Network for Polyphonic Piano Music Transcription(2016)
Onsets and Frames: Dual-Objective Piano Transcription(2018谷歌)
High-resolution Piano Transcription with Pedals by Regressing Onset and Offset Times(2020字节)
除了文章本身,还参考了一琳同学的周报和舒心师姐的周报
An End-to-End Neural Network for Polyphonic Piano Music Transcription
一个CNN与RNN结合的端到端的钢琴演奏音乐转录模型。模型分为两部分:声学模型(acoustic model)与音乐语言模型(music language model);这个模型结构是与语音识别系统类同的。声学模型与音乐语言模型之间通过一个概率图模型组合起来,最后使用波束搜索算法来在模型的输出上得到推断结果。
本文总结了一些过去的AMT(自动音乐转录)模型,所提出的模型也是后续许多新模型的基础。
声学模型
声学模型输入特征$x$,输出$P(y$|$x)$,其中$y$是一个高维向量,其分量分别对应于$x$在钢琴键的各音高上的可能性。经过一番讨论,最终文章选用的声学模型是一个卷积神经网络。选择CNN的原因主要是它在为输入音频的一个帧做出音高预测时,能够同时提取与这一帧相邻的多个帧的时域与频域特征,这与音乐的特性是相适应的。
音乐语言模型
音乐语言模型的输入是音符的时间序列$y$($y_t$是一个高维二值向量,表示$t$时刻所有活跃的音高),输出是$y$的概率分布$P(y)$。对于多调音乐(polyphonic music),同时活跃的音高是具有高度的相关性的,它们可能组成一个和弦,或是满足某一调式。
序列$y$的每一个值都是一个能表示钢琴所有音高中哪一个正在活跃的高维向量,要为这样的序列生成概率分布,需要使用RNN与NADE结合的模型。RNN与NADE都可以为输入找到概率分布,但RNN是为一个序列寻找,NADE是为一组高维输入寻找。直接使用RNN来为高维向量序列推测概率分布,则向量的各分量之间依然是独立的,在AMT问题里就相当于独立地看待同一时刻下活跃的音符,这就没有将音律的问题利用起来;而NADE在推测概率分布时并不考虑输入的顺序,即它将输入看作是一个无序的组而不是有序的序列。两者结合的RNN-NADE模型就能够比较好地推测高维向量时间序列的分布,结合方式简单来说就是让一系列的NADE在RNN的约束下学习。
Hybrid RNN
将声学模型和音乐语言模型用概率图模型组合起来,就得到本文真正要提出的Hybrid RNN模型。在独立性假设
$P(y_t$|$y^{t-1}_0, x^{t-1}_0)=P(y_t$|$y_0^{t-1})$
$P(x_t$|$y_0^t,x_0^{t-1})=P(x_t$|$y_t)$
下可以得到
$P(y$|$x)\propto P(y_0$|$x_0)\prod^T_{t=1}P(y_t$|$y_0^{t-1})P(y_t$|$x_t)$
其中$P(y_t$|$x_t)$即输入$x_t$时对输出的预测,通过声学模型得到;$P(y_t$|$y_0^{t-1})$即序列中考虑前后全部序列信息后对输出的预测,通过音乐语言模型得到。
Conclusions and Future Work
作者提出的部分问题与未来改进方向:
- AMT问题的有标签数据集太少
- 输入目前用的是CQT,改用VQT等具有更高时间分辨率的输入表示可能有帮助(2020年有个工作Automatic Music Transcription for Two Instruments based Variable Q-Transform and Deep Learning methods)
- 音乐语言模型里对调式的考虑还不够,可以对模型使用变调的输入来训练,或者是针对不同调式训练不同的模型
- 音乐语言模型的网络结构还可以改进,比如把输入层改成卷积层
Onsets and Frames: Dual-Objective Piano Transcription
这是一个利用深度卷积与循环神经网络赖完成多调的钢琴演奏转录工作的项目。这一模型的特别之处在于,它预测音高的开始事件(onset),然后利用这些预测来训练音高的逐帧识别;具体来说,就是在一个帧里,帧识别器不能推理一个音符的开始,除非onset检测器认可这一帧中存在onset。在训练模型的过程中,作者注意同时加强onset以及偏移量(指音符持续量)的检测效果。
需要注意这里是对钢琴音符做起始位置识别;之所以能够这样做来提高AMT模型准确率,很大程度上还是和钢琴音符本身的特点有关系。钢琴音符的起始位置恰好就是音符振幅的峰值,且具有标志性的宽带频谱,所以识别钢琴演奏中的音符起始位置比较简单;同时钢琴敲键发声的原理也使得模型能够根据音符起始事件发生的速度来推断音符的音量,敲键快通常意味着这一音符的音量大,利用这一点转录生成的音频能够更好地记录钢琴演奏中的强度变化,结果更自然有感情(实际上演奏强度本来就是钢琴谱的一部分,如果说AMT的直接目的就是生成琴谱,那演奏强度本来就应该记录下来)。
网络框架
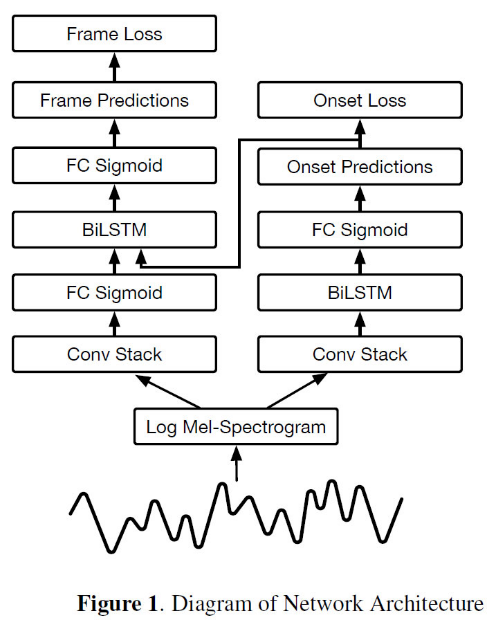
模型的输入为229 mel-bins,2048 FFT Window size,16000Hz采样率的频谱结果。
onset检测器:卷积层的输出作为128 units双向LSTM的输入,LSTM后接一个88维输出的全连接层,88维的输出表示88个钢琴音高的onset概率
framewise检测器:卷积层接一个88维输出的全连接层,88维的输出向量和onset检测器端的对88个音高的onset预测向量级联成一个176维的向量,再过一个88维输出的全连接层。
LSTM(long short term网络)是一种特殊的RNN,它和简单RNN相比能够学习到连接更远的信息;双向的RNN是由两个RNN上下叠加在一起组成的,对于每个时刻t,输入会同时提供给两个方向相反的RNN,输出由两个RNN的状态共同决定,双向LSTM也是一样的。
损失函数
好复杂,没懂,待补充……
High-resolution Piano Transcription with Pedals by Regressing Onset and Offset Times
如题目所说,与谷歌的项目相比提高了onset检测的时间分辨率(从帧到毫秒),且增加了对延音踏板的转录。
为什么要提高onset检测的分辨率?以谷歌的模型为例,它只找到并标出onset事件发生的帧,不能给出具体发生的时刻,进而不能给出音符attack的持续时间;另一方面,很自然的,对于逐帧的转录模型的转录结果,其分辨率会受帧长选择的影响,为了提高结果的时间分辨率而一味缩短帧长又会提高计算开销。
本文提高检测分辨率的方式是,定义每帧的target值为此帧的中间时刻到最近的onset时刻的时间。
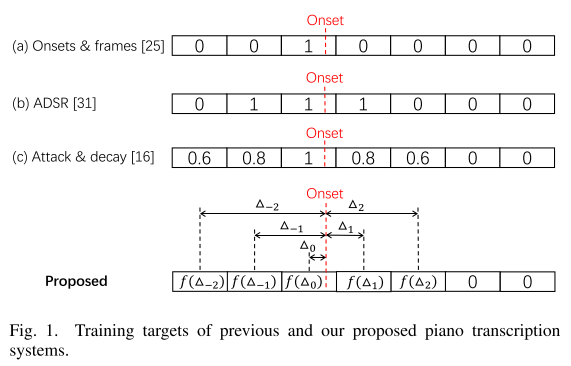
网络框架
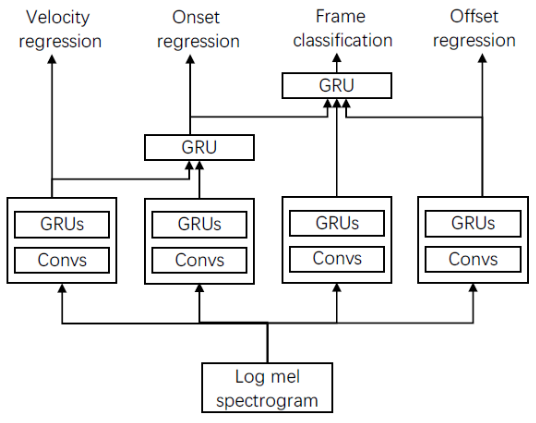
还看不太懂,待补充……
文档信息
- 本文作者:Jingwen Huang
- 本文链接:https://uangjw.github.io/2021/10/21/AMT-DL-3models/
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)